The issue stays primary
Most tools make you search for the problem. FaultLens starts with it: the production issue that needs explaining, not a broad telemetry hunt.
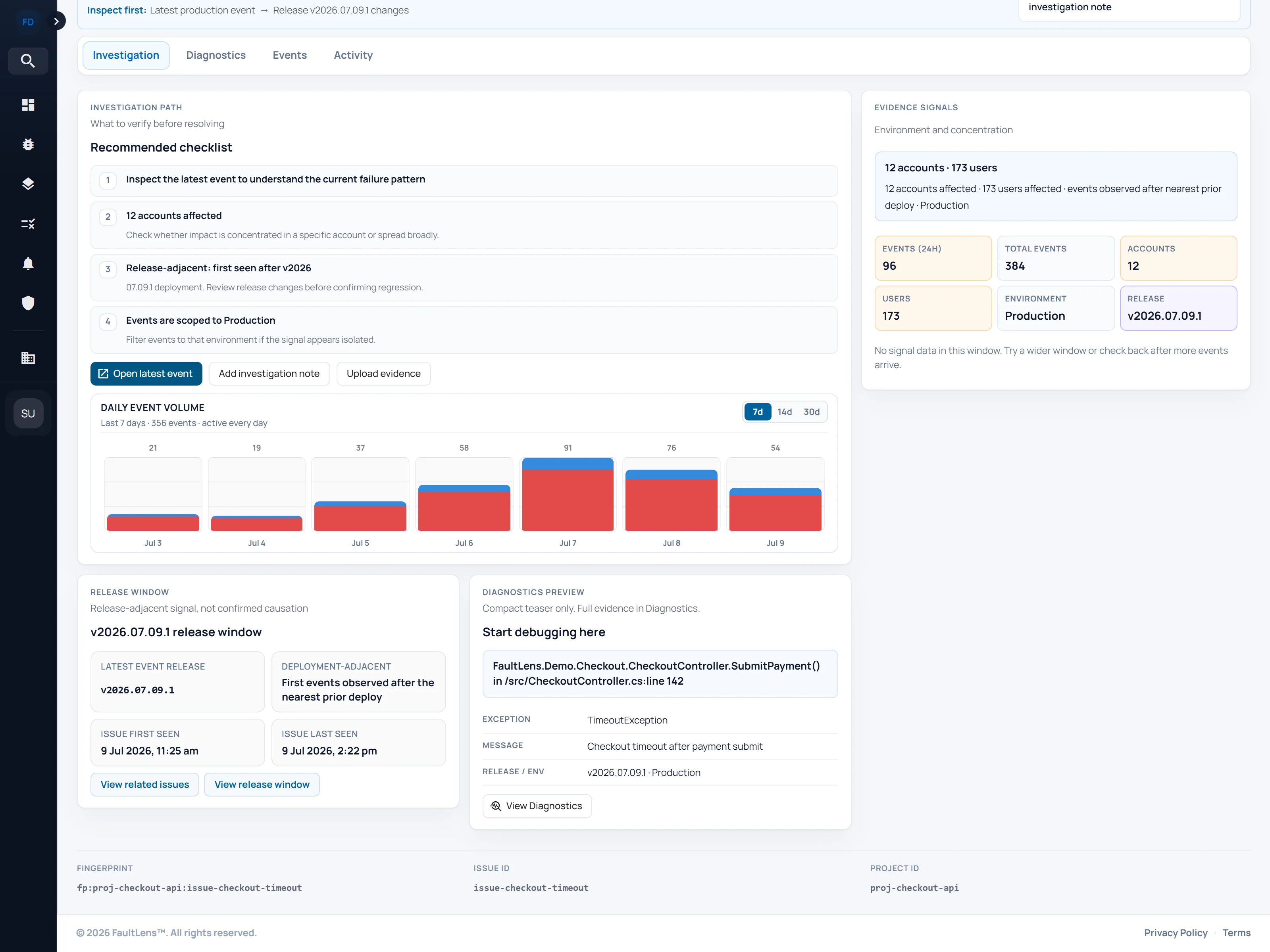
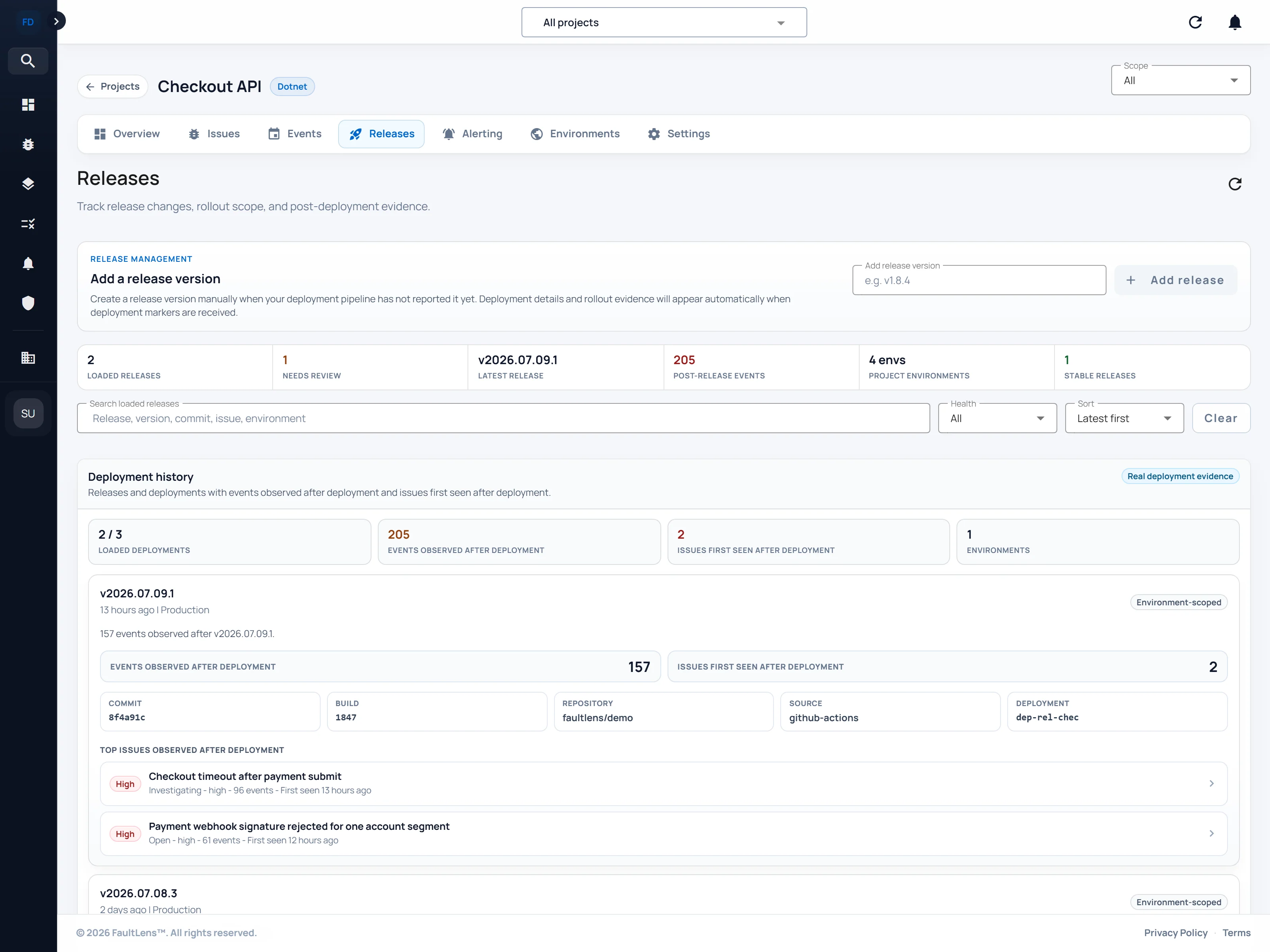
When production breaks, the first half-hour disappears into Slack threads, git blame, and whatever the last engineer remembers about the deployment. FaultLens keeps errors, releases, environments, and issue context connected in one investigation trail so your team can act instead of reconstruct.
Request access. If FaultLens fits your workflow, we will reach out with guided onboarding.
The first 20 minutes of a production incident often disappear into Slack, git blame, and whatever the last engineer remembers about the deployment. FaultLens keeps that context attached to the issue before the team has to reconstruct it by hand.
Most tools make you search for the problem. FaultLens starts with it: the production issue that needs explaining, not a broad telemetry hunt.
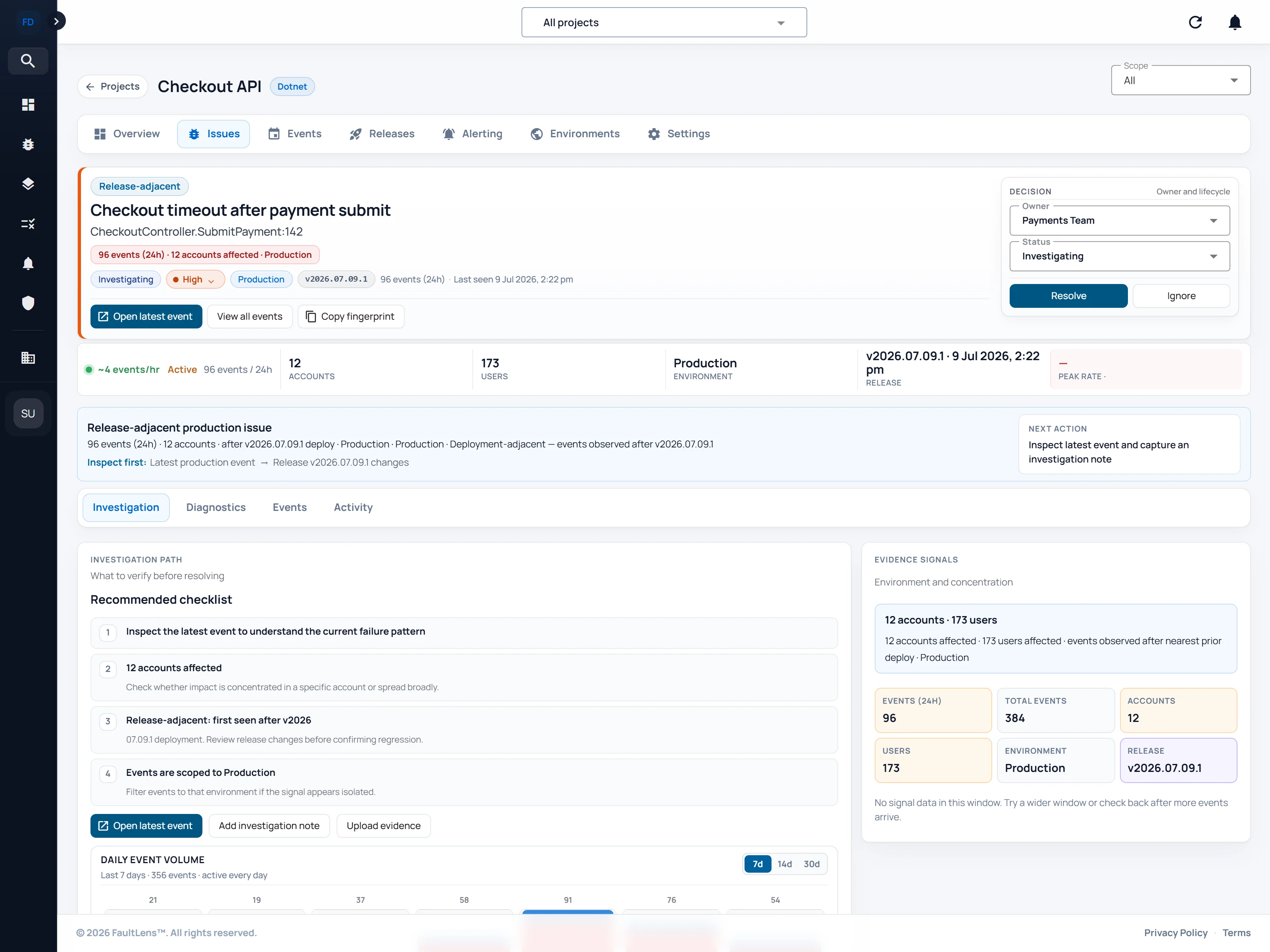
Release changes, environment differences, and investigation notes stay near the issue instead of being rebuilt from memory and scattered tabs each time.
We'd rather do one thing well than build a platform that does everything badly. FaultLens is intentionally narrower so the path to a diagnosis is shorter.
Start with the issue. Pull in what changed. Check the environment. Leave with a clear next action. The whole path stays in one place so the team does not have to piece the story together again.
A production error appears. Do not start a search. Open the issue that needs explaining and stay anchored to it.
Bring recent deployment history into the same view while the issue is still in front of you. See what changed without switching tools.
Check runtime differences before the diagnosis drifts. Production vs staging. EU vs US. Keep the signal close to the issue.
Leave knowing what to check next, not with a pile of half-closed tabs and a Slack thread to re-read tomorrow.
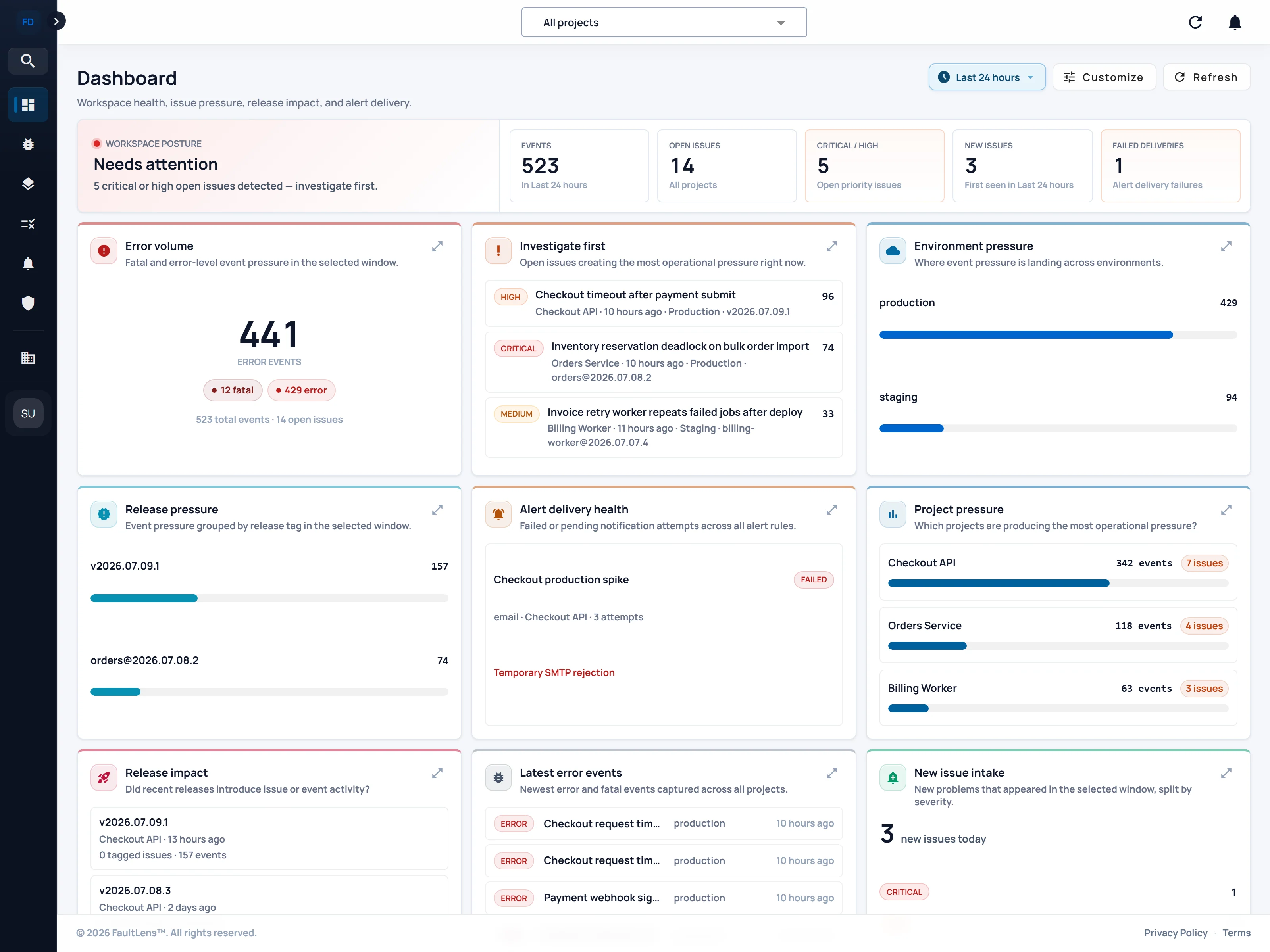
The workflow begins with the production problem that needs explaining, not a hunt across dashboards.
Teams can see what changed and where it changed without reconstructing the path from memory.
That makes handoff easier and repeat incidents easier to understand when they happen again.
Release evidence gets enough room to be readable while keeping the deployment and issue story connected.
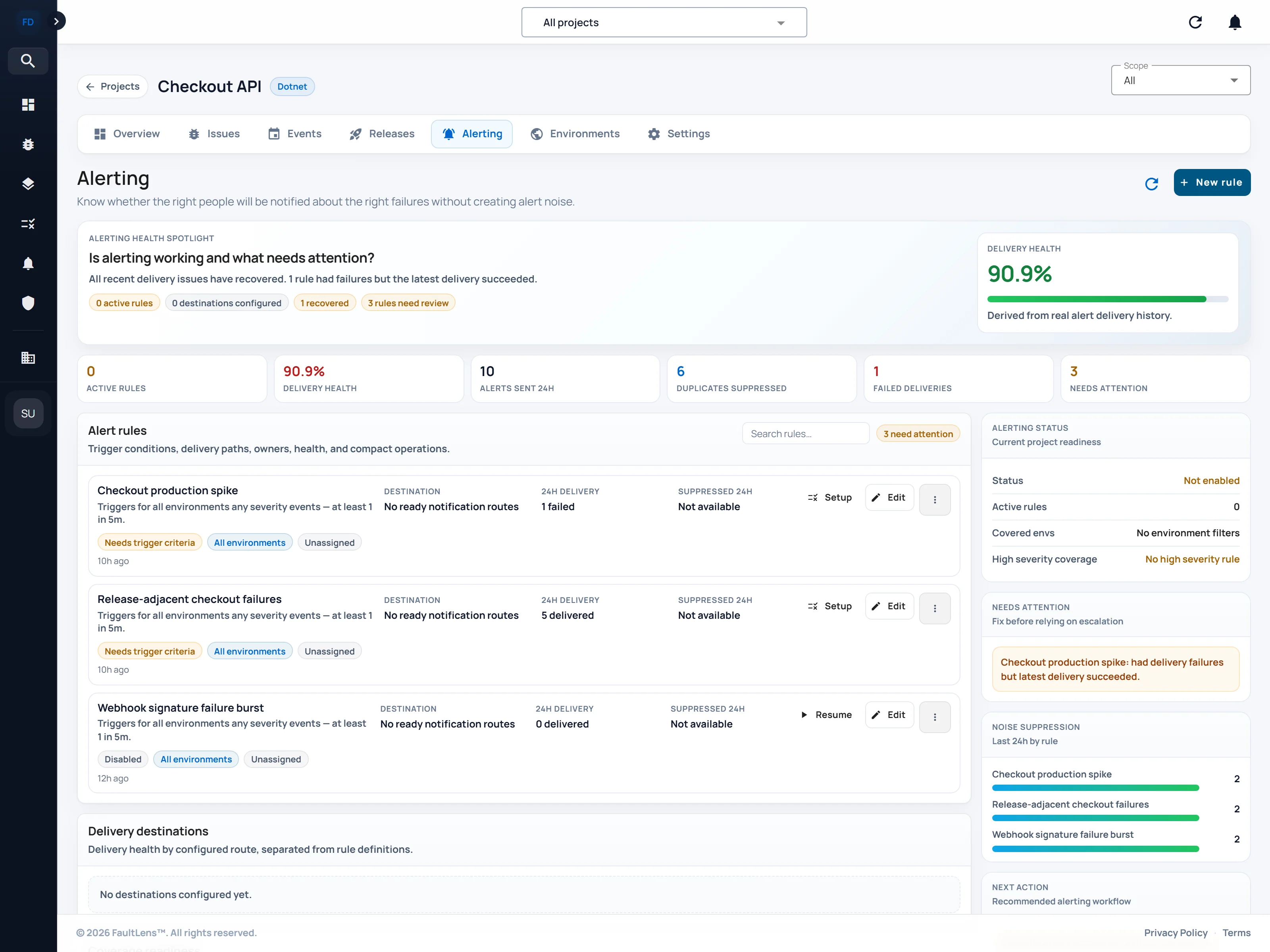
Some teams come to FaultLens from error monitoring. Others arrive after a release-related incident where the trail was too scattered. These paths keep the next step practical.
Understand the focused product areas before going deep into SDK setup.
Review runtime-specific guidance for backend, frontend, and SaaS application teams.
Use the overview and docs when you need a quick product definition or implementation path.
Use an official SDK where available, or integrate directly using the HTTP ingestion API. Official SDKs cover .NET, TypeScript / JavaScript, React, and Angular. Every other language and runtime sends the same event envelope to the same endpoint. Sample repositories let you validate a working integration before wiring your own application.
NuGet package for .NET applications. Captures exceptions, breadcrumbs, release, environment, and request context without interrupting application flow.
dotnet add package FaultLens.SDKJavaScript browser SDK for capturing client-side errors with route, referrer, user agent, user ID, and tag context.
npm install @faultlenshq/browser@1.0.0Angular error handler package built on top of the browser SDK. Captures Angular-specific diagnostics context with provideFaultLens and FaultLensService.
npm install @faultlenshq/angular@1.0.0 @faultlenshq/browser@1.0.0React SDK with provider, hook, and ErrorBoundary APIs on top of the browser SDK. Supports React 18 and React 19 applications.
npm install @faultlenshq/react@1.0.0 @faultlenshq/browser@1.0.0No official SDK for your stack? POST the canonical event envelope from Java, Python, Go, PHP, Ruby, Rust, C++, or any runtime that can make an authenticated HTTPS request. Same endpoint and same contract as the SDKs.
POST /api/events/ingestStarter and Growth are the public paid plans. Activation is confirmed with the FaultLens team. Talk to us directly at hello@faultlens.in and we will reply within one business day.
Validate FaultLens in a real production diagnosis workflow before moving to a paid plan.
Request trial →Higher event volume, longer retention, broader rollout planning, or advanced commercial handling. One direct contact path.
Contact sales →Built with practical SaaS security fundamentals.
The product is designed around focus over breadth, context over tool sprawl, and practical diagnosis over platform theater.
If your team spent the first half-hour of a production issue figuring out what changed instead of fixing it, FaultLens is built for that exact problem. Join the waitlist or talk to us directly at hello@faultlens.in.
FaultLens is in selective early access for SaaS engineering teams that want a calmer, issue-led diagnosis workflow. Leave a work email and we will reach out when rollout opens for the right fit.
FaultLens is introduced carefully through direct conversations, guided onboarding, and honest fit checks for teams with recurring production diagnosis work.
If production diagnosis is costing your team time it should not, leave a work email and a little team context. If FaultLens fits the way you debug, we will reach out with next steps.